
Text search with CQPweb
On this page we introduce the program which handles text search for the edition, and indeed for other historical English corpora and many others too, CQPweb. (CQP stands for Corpus Query Processor.) Lancaster University's CQPweb server holds an indexed copy of the corpus created for the project by Sebastian Hoffmann. You'll find it under ‘Historical English’ on their homepage.
Enabling CQPweb
- Before first use. Go to the CQPweb User Page to log in or to register, here. Check the box Stay logged in on this computer.
- If already logged in, go straight to the CQPweb search page for The Mary Hamilton Papers, here.
- See some sample CQPweb searches of The Mary Hamilton Papers, here. (New search options added 20 September 2024, 21 January 2025.)
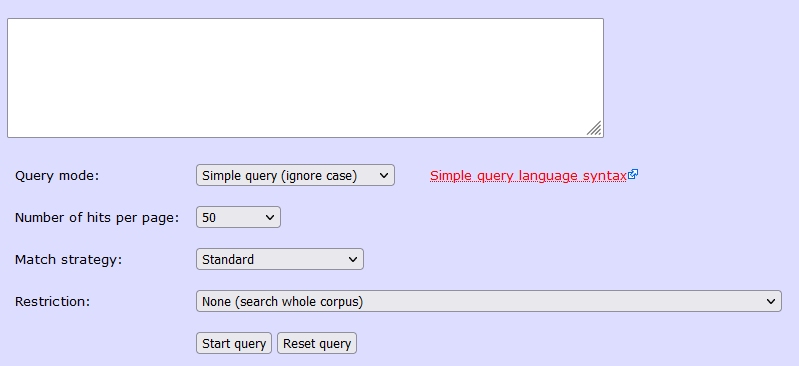
Search page
Using CQPweb
The default is a Simple query (ignore case). Just type your search term in the box, whether a word or phrase, and click Start query. Hits will appear in a KWIC concordance showing 10 words either side of the search term. You can click on the underlined keyword(s) in column 3 to view that hit with several lines of context, still within CQPweb. The default view there is similar to normalised transcription in the edition, while alternative view is like diplomatic. You can widen the context further (click Choose action…) — more than once if necessary. Your choices of view and context width in CQPweb are ‘sticky’ — that is, they become your default until/unless changed.
Alternatively, clicking the open-book icon 📖 in column 1 of the concordance will open MDC in a new tab in your browser, displaying the exact page in the edition where the search term is found.
In CQPweb you are searching a version of the normalised text, so use modern British spelling for words other than proper names. The CQPweb search and the concordance display organise the corpus into grammatical tokens like honour, discussed, negative n't, possessive 's. Incomplete words will not be found. Thus a search for hono will find nothing — instead use hono* or hono+ (where * means 0 or more characters and + means 1 or more), finding honour, honours, honouring, honoured, honorable. Likewise, a search for do will find do but not does, doing, Doctor, Douglas, etc.
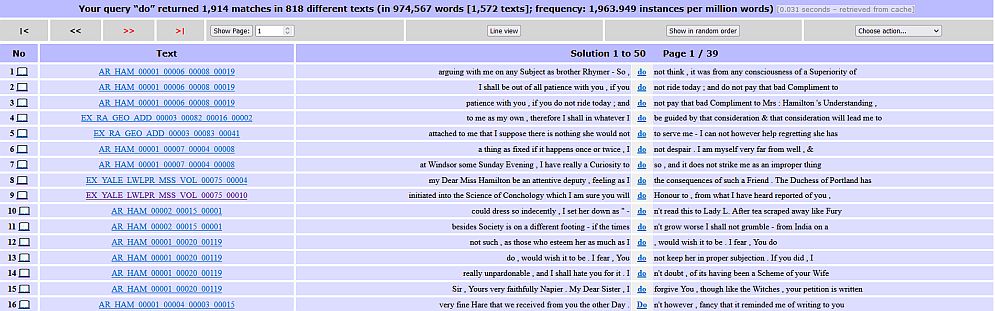
KWIC concordance
Some of the hits have do followed by n't (separated in the concordance but re-joined as don't in the context view). To find don't or original dont directly, enter do n't as separate tokens.
For many users the Simple search facility can be exactly that: you just type a word and instantly find every occurrence in the corpus. But it also encompasses rather more elaborate searches, including wildcards like ? * +, proximity searches, part-of-speech searches, alternative search terms, and so on. A clear, general guide to Simple search syntax can be found here, and a Help system and video tutorials for CQPweb can be found from the left panel of the search page.
All your searches can be recalled (click Query history in the left panel), allowing you to re-run or adapt a past search. And clicking Show in CQP syntax at the top of the list allows you to run the same search in the rather more technical CQP syntax and perhaps combine it with some of the additional possibilities available there, including searches for persons, place-names, dates, foreign words, literary quotations and much else besides. We have prepared a page here with some examples of simple and CQP searches in The Mary Hamilton Papers that you might wish to adapt.
Coverage
The then-available transcriptions were indexed for CQPweb by Sebastian Hoffmann for the last time on 10 November 2023. CQPweb gives a ‘word’ count (actually a token count) of 974,567 for the normalised text. Our own word count was 875,436. The downloadable Excel spreadsheet indicates (with hyperlinks) all files currently available in MDC, with individual (actual) word counts.
Please note that the corrections incorporated in the edition on 29 July 2024 and 5 June 2026 (the latter also adding another 118 transcriptions, bringing our word count up to 900,169) are not covered by the indexed material in CQPweb. There are no plans at present to re-index the edition for CQPweb.